

















")







I've recently deployed a new spam filter at work and I'm rather proud of the results after the first few weeks. This blog post ought to be useful to at least someone who gets here by way of a Google search at some point I hope.
The new server is setup as my company's MX and relays mail inside the network as appropriate, but obviously only after it's been accepted. One key part of the design is to check all mail for a valid destination, viruses, and spam likelihood before it's ever accepted for delivery.
The first big benefit here is that our servers have been heavily bogged down in the past by generating and attempting to deliver bounces for messages ultimately not going anywhere. With multiple potential server destinations for traffic, it's always been too difficult to determine if a destination address was legitimate before relaying it on to the internal destination server, which would bounce it. This was made worse when viruses and spam messages were sent to legitimate, but machine-operated list administration addresses for hundreds of mailing lists that were very widely published.
All this meant that a key aspect of getting good results was that messages be scanned and checked in real-time as they come in. I wanted to ensure that any needed bounce messages were the responsibility of the sending server, but that means that a lot of work for our server.
The initial setup worked great, but I had load problems with Bayesian spam filtering. SpamAssassin's Bayesian filtering really really does a lot of database access with so much traffic as we push through it. At first, I was using the standard BDB file databases. Locking became a big problem fast when deployed under load. Next, I switched to using flock (instead of the NFS-safe locking) for the databases and I didn't notice a change. I converted the databases to MySQL, using MyISAM. This lasted longer, but eventually after a few hours developed a large enough database that table locking became a really limiting factor. I converted those databases to InnoDB, which should have helped with it's ability to use row-level locking. It lasted longer again, but only about a day or so before it got out of hand. Finally, I gave up and disabled Bayesian filtering and let SpamAssassin do all the other stuff it did, but a little more spam was getting through and I wanted to get it working.
That's the setup, in a nutshell. The solution I came up with was to use two databases. The premise of my adjustment is that a Bayesian database that is static but only a few hours or even a day old ought to be accurate enough for the decision-making on incoming spam detection. I created two databases, both using MyISAM for it's quick insert/select capacity. One is called spamassassin and is configured as a normal database. The other is called spamassassin_read and is used as the read-only decision-making database. I hacked up the SQL.pm file a bit that SpamAssassin uses to query the BayesStore module databases, so that all the select queries in the decision-making functions were coming from spamassassin_read, while all the storage functions that were learning from new messages were writing into the normal spamassassin database.
Finally, I setup a script that operates in a couple steps. First, it adjusts the SpamAssassin configuration file (local.cf) so that it stops using Bayesian filtering altogether and reloads SpamAssassin. It waits a few seconds for any potential ongoing queries to stop, sends a FLUSH TABLES; command to the MySQL server, then rsyncs the spamassassin writeable database to the spamassassin_read database. It packs the spamassassin_read tables with myisampack, to make them even more optimized for read performance, and then it reindexes the tables as necessary. Finally, it turns Bayesian filtering back on in the local.cf configuration file and reloads SpamAssassin again.
All in all, the script takes a few minutes to run. During that time, SpamAssassin is still running and letting mail in, but it's just slightly less effective without Bayesian filtering. There's no downtime, just slightly less effectiveness for a few minutes. Each time the script runs, the decision-making database (spamassassin_read) is refreshed with up-to-date information.
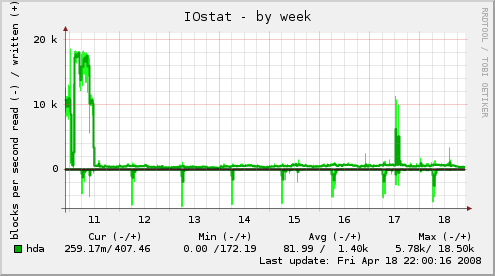
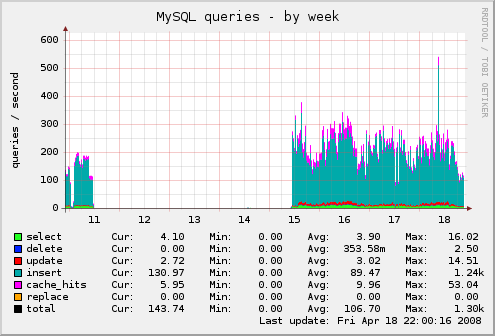
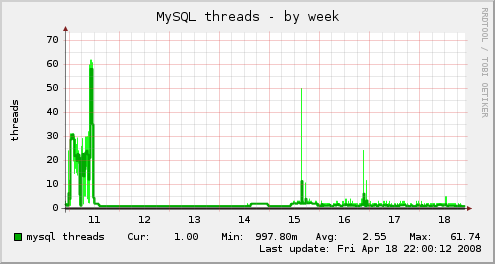
I've attached a number of weekly graphs of various server statistics. The server in question here is running with 2GB of memory and dual AMD Athlon MP 1600+ processors and a 200GB IDE disk. It's by no means the fastest machine around, but decently capable. The problems I had before are at the left of the graphs and are pretty easy to spot. The latest performance numbers are more toward the right.
Just about everything with CPU load, process counts, MySQL throughput and slow query counts, memory usage, general IO, open network connections, etc are showing much improved performance. The MySQL query types and throughput are the most telling, as you can see that a _lot_ more traffic is going into and coming out of the MySQL server than it was last week, but it's not having trouble keeping up with the load at all. Last week, the server became almost entirely unresponsive with much less throughput.
I hope this helps someone - I'm very happy with it.
| Attachment | Size |
|---|---|
| 39.15 KB | |
| 28.75 KB | |
| 64.55 KB | |
| 32.2 KB | |
| 34.62 KB | |
| 22.03 KB | |
| 24.44 KB | |
| 45.8 KB | |
| 36.07 KB |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}